I have an AllStarLink node setup on a Linode Debian 12 computer. Almost 100% of the time, the AllStarLink node is just idling with a maximum of 1 or 2 users. Periodically, I get an email from the Linode system “Your Linode, has exceeded the notification threshold (90) for CPU Usage by averaging 100.0% for the last 2 hours.” This has also occurred when there are zero users connected. I get the email alert of high CPU usage on the minimal CPU shared computer from 1 to 4 times per month. As far as I know, there’s almost no activity on the AllStarLink node almost 100% of the time. Yet, I keep periodically receiving the high CPU alerts from Linode. I wonder if anyone else that has a Linode AllStarLink Node on the smallest shared Linode Debian Linux 12 computer, with almost zero AllStarLink usage, also receives the 100% sustained CPU alerts. What could be causing the extreme CPU usage? Is there any way to adjust the Linux Debian 12 operating system, or ASL3, so that the intermittent extreme CPU conditions do not occur? If some kind of periodic computing process is occurring, perhaps the CPU priorty level could be lowered.
Many years ago, I experienced extreme CPU load while transcoding video files on a home Windows computer. The load was so intense that the mouse and keyboard could not be used at all. There are 7 CPU priorty levels with Windows, and the video transcoding process was set to the mid range CPU priority. To fix the problem, I changed the video transcoding process from normal priorty to low priorty. That fixed the keyboard and mouse lockup problem. It also caused the video transcoding to take a little longer time to process. This only took one line of code to change the pirority.
Later, I ran into the same problem at my work administrating Windows servers. My company’s application ran a batch job to run a daily report which locked up all the servers users for long time period while the batch job was running. I gave our company’s developers the one line of code to lower the batch job priorty. After the developers lowerer the batch job priorty, the server user lockup problem ended and never reoccurred. This fixed the user lockup problem on 100 Windows servers that were running the company’s custom application. The change took a daily report about 1/3 longer to run, but that didn’t matter because it was a daily report. But it immediately fixed hundreds of end user complants.
Perhaps there is a periodic batch job type process that’s running in Debian 12 to control a batch job in the ASL3 application that intermittently spikes the CPU consumption for two hours. If that’s the cause for the extended CPU consumption, then it may be possible to fix that problem by lowering the CPU priorty level for that batch job.
Even bug #420 I’ve never seen it create CPU spikes.
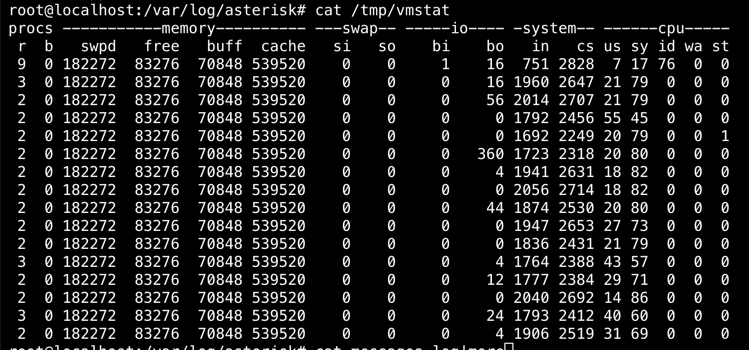
If you run top -d1 and watch it for awhile, do you ever see the asterisk process take more than 15% in the %CPU column? You can also capture a log-running vmstat 1 > /tmp/vmstat and then look under “cpu” at the “us” and “sy” fields.That will tell you overall if the box is actually busy.
Finally, what’s the output of uptime say, specifically the “load average” counters.
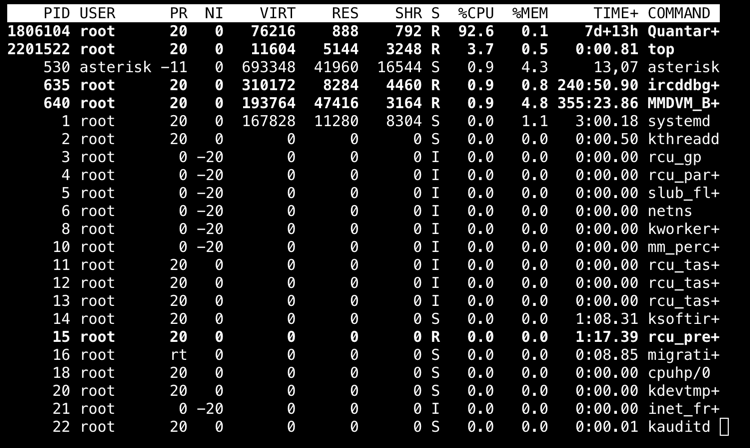
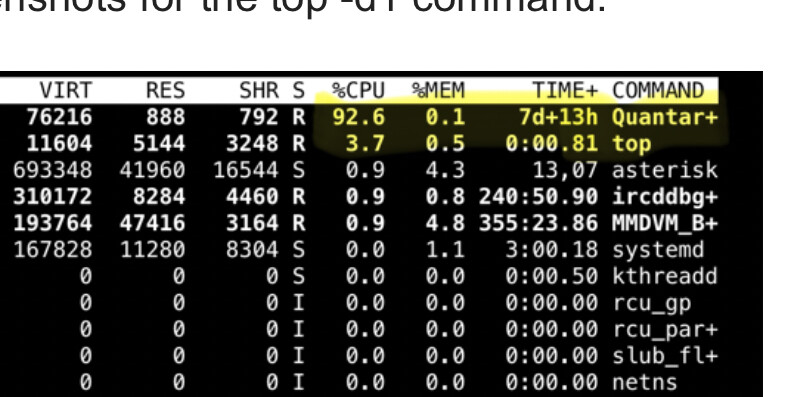
The asterick process is generally between 0.9% to 1.9%.
In vmstat the us is 7 - 55 and sy is 17 - 82
I’m wondering if a possible solution is to delete the log files, then reboot.
I think I could schedule a job to do that on a daily or weekly basis with a cron job. The 610480 AllStarLink node is a running on a Linode Nanode 1 GB, the smallest shared Linode cloud computer. The specs are 1 gig ram, a CPU, 25 gigs storage, 1 TB transfer, network 40 gigs down, 1 gig up. I receive the high CPU for two hours email alert from Linode 1 to 4 times per month.
It appears that quantar+ software, likely used to program the radio continues to run in the background, perhaps as a monitoring or log service ?
Find the PID and kill it if it is not needed.
My bets are it will reload on reboot so you need to find and disable the service and/or uninstall/remove it.
Killing the PID would be a first logical step.
Quantar Bridge is part of DVSwitch Server. You don’t need it unless you are interfacing to a Quantar repeater.
You can safely disable the service:
sudo systemctl stop quantar_bridge
sudo systemctl disable quantar_bridge
How is Racknerd about overselling their hosts?
I have a Racknerd, and find it has some strange network routes and hehavior compared to my Linodes. I don’t run ASL on it. Almost my entire stack runs on dedicated servers these days, since I was getting really tired of the oversold shared resources of VPS’s. Less of a problem when you move to higher price brackets, but hosting a high number of connections, I found the bottom tier plans to struggle a bit when noisy neighbors on the same host were doing heavy tasks. Since CPU is dynamic, you don’t always have the same resources available. A spike on someone else’s virtual machine will decrease the availability of resources on your own machine. You can see this fluctuate while running a task where the CPU is pegged at a specific point.
I tried running ASL on Linode, Digital Ocean and Vultr, and saw the same thing over and over again.
Lots of tasks running on neighboring virtual hosts every 15 minutes, especially at the top of the hour, would cause audible jitter. Sometimes, moving to another physical host would fix it for a while, until that host eventually became saturated. Moving up to the next price bracket usually helped, because there are less guest machines running on the hosts the higher up in price you go.
I do still use a couple of Linode Nanodes for light traffic, and they are OK for that.